Redis的主从复制
概述
Redis 的主从复制是 Redis 官方推出的分布式机制,解决了部分集群问题。
官方后续的一些分布式的实现,包括 Sentinel 以及 Cluster 等,多多少少都用到了复制的功能。
思维脑图
相关实现
查看节点主从信息
通过指令 info replication,可以单独查看服务器此时的主从信息。如下:
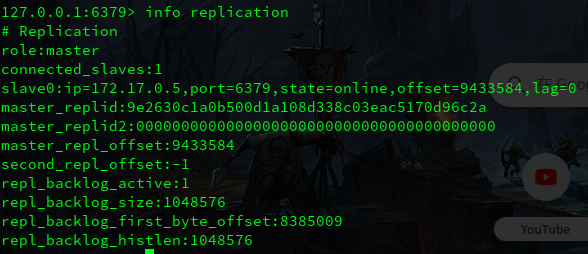
role 表示当前节点的身份,master 表示是主节点
connected_slave 表示当前的子节点数,以及 slave0 就表示子节点信息。
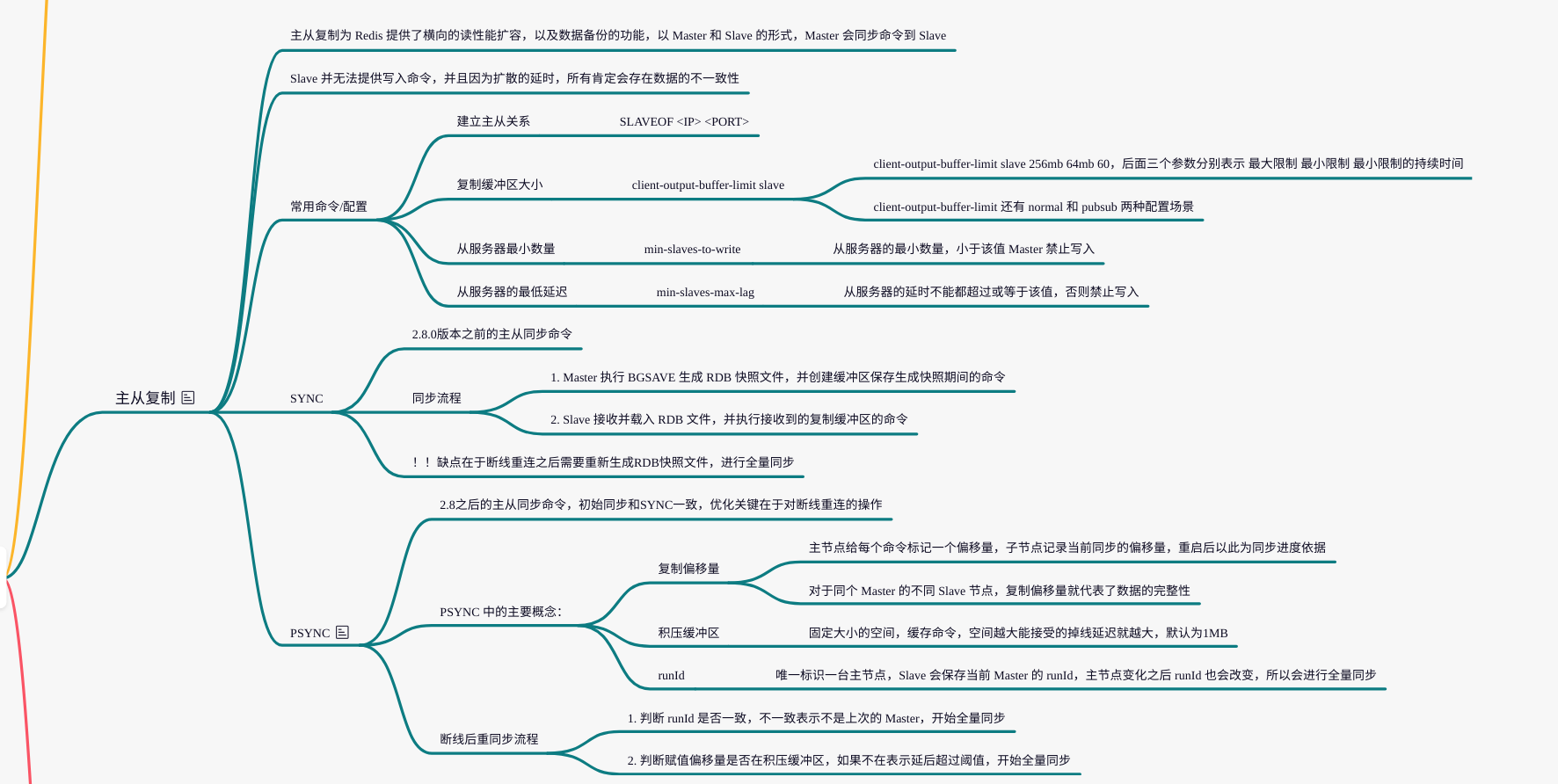
主从关系的建立
Redis 服务器可以通过 SLAVEOF <ip> <port> 命令或者配置文件中 slavof <ip> <port> 的方式,建立主从关系。
被复制的服务器称为主服务器,当前服务器则称为从服务器。
需要注意的是,Redis 只支持一主多从的方式,一个从服务器只能对应一个主服务器。
建立主从关系之后,从服务器就无法再执行写命令了,而是完全同步主服务器的数据。
即使在执行 AOF 或者 RDB 文件的过程中发现有过期的键也不会主动删除,只能等主服务器的同步。
因为无法执行命令,无法写入,所以主从模式仅仅只扩展了读属性,写入瓶颈依然存在。
该种主从复制模型非常适合读多写少的环境,复制相当于为主服务器中的数据创建多个复本,也算是一种容错策略。
单点的写入也一定程度上保证了一致性的要求。
这里的一致性都是指最终一致性,因为命令的扩散也会有延迟,卡着延迟从从服务器中读取就会有数据不一致的问题。
因此如果对一致性的要求很高,或者必须要强一致性,建议不要从从服务器读取。
复制模式可以分为数据同步以及命令传播两个阶段。
数据同步就是从服务器刚开始连接时的操作,全盘同步主服务器上的数据。
命令传播就是主服务器将本地执行过的命令再发送到从服务器(主服务器以客户端的身份发送命令到从服务器)。
Redis 中对应数据同步的命令有两个 SYNC 和 PSYNC。
SYNC - 旧版复制
旧版的数据同步就是依托于 SYNC 命令,从服务器向主服务器发送该命令表示开启同步数据流程。
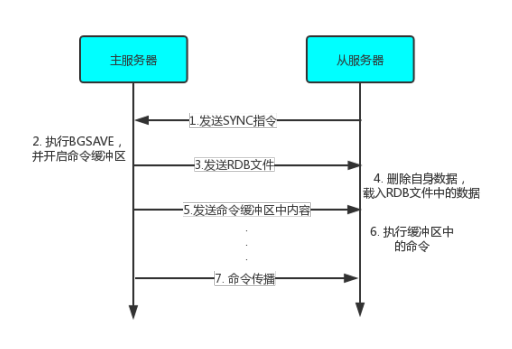
主服务器首次接收到 SYNC 命令之后,会执行 BGSAVE 命令生成 RDB 文件,并在此时开启命令缓冲区,记录备份期间所有执行的写命令。
BGSAVE 执行完之后,会将生成的RDB文件发送给从服务器。
此时如果于多个从服务器连接,RDB 文件是可以直接共享的。
从服务器在接收到主服务器发送的 RDB 文件之后,会清空本地的所有数据,全盘载入 RDB 文件中的数据。
之后主服务器还会将缓冲区中的数据发送到从服务器,从服务器执行完缓冲区中的写命令,就达到了和主服务器的完全一致。
旧版的复制很简单,主要就是生成 RDB 文件并传播指令。
问题就在于太过简单,即使网络波动导致的瞬时断连,在重连之后也会进行全量同步。
PSYNC - 新版本的数据同步
PSYNC 命令是对 SYNC 命令的进一步优化,主要是 SYNC 只能进行全量同步,效率真的就不高,为此在 Redis2.8 版本之后,新增加了一个 PSYNC 命令。
PSYNC 命令完整的形式是 PSYNC <runid> <offest>,在全量同步的基础上增加了一个增量同步的过程判断。
</br>
下面是增量同步中增加的概念:
复制偏移量
按照字面意思也很好理解,是主从服务器各自维护的以字节为单位的属性,表示复制的进度。
比如当前主服务器的复制偏移量为10000,在发送了50个字节的内容之后,就变为了10050,可以认为是主从服务器数据不一致性程度的表示。
在 Sentinel 执行故障转移的时候也会以复制偏移量作为主要的参考依据。
一定程度上,复制偏移量就表示从节点数据的完整性。
复制缓冲区
复制缓冲区是由主服务器维护的一个固定长度的 FIFO 队列,该队列会缓存近期主服务器所执行的写命令。
主服务器 run ID
run ID 唯一标识一个 Redis 服务器。
实际上不论主从在服务器启动时都会生成一个 run ID,由40位随机的16进制字符组成。
此处的 run ID 是在从服务器连接到主服务器是由主服务器下发的自身的 run ID,重连之后通过判断 run ID 来确定是否为同一个 Master。
PSYNC 的执行流程简述如下:
- 判断 run ID 是否相同,不相同会直接开启全量同步的逻辑,相当于直接走 SYNC。
- run ID 相同表示是断线重连,判断复制偏移量是否还在复制缓冲区中,如果超出表示超时时间过长,也需要走 SYNC。
- 如果复制偏移量未超出复制缓冲区,则直接将复制缓冲区中的命令发送到从服务器,从而避免全量同步。
Q&A
Q: 主从模式的优势
- 读性能横向扩展
- 数据备份,保证数据不丢失
Q: 主从模式的存在的问题
- 单点故障问题(Redis 只支持一主多从或者一主一从的模式,并且写命令必须由主节点处理
- 数据不一致问题(命令扩散其间主从数据并不一致,主从模式仅保证最终一致性
- 内存限制问题(不论主还是从都是单机保存一份完整的数据,并没有做分片,Redis 集群的内存大小仍受单机内存限制
Q: PSYNC 的优化
PSYNC 借由复制缓冲区实现了对断线重连的容忍机制,如果断线时间断,可以从复制缓冲区中找到缺失的命令就可以进行部分重同步,而避免每次都是全量同步。