垃圾收集器整理
概览
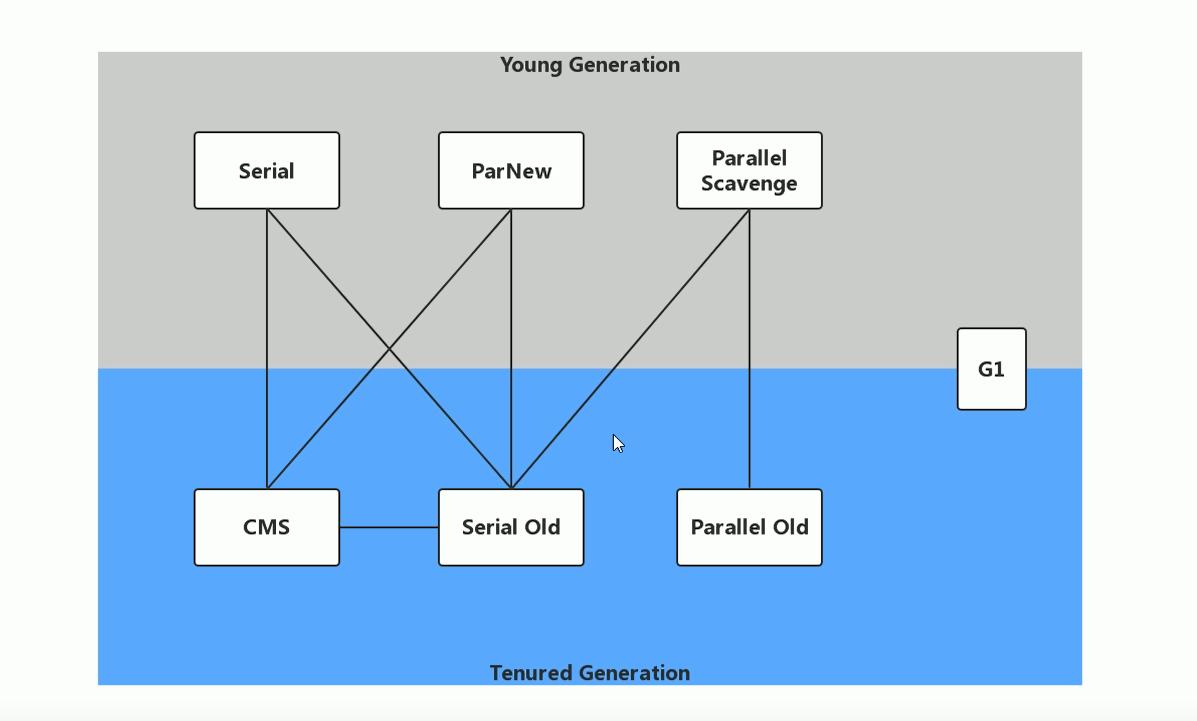
垃圾收集器组合
| 参数 | 垃圾收集器 |
|---|---|
| -XX:+UseSerialGC | Serial New + Serial Old |
| -XX:+UseParNewGC | ParNew + Serial Old |
| -XX:+UseParallelGC | Parallel Scavenge + Parallel Old |
| -XX:+UseParallelOldGC | Parallel Scavenge + Parallel Old |
| -XX:+UseG1GC | G1 |
| -XX:+UseConcMarkSweepGC | CMS |
ZGC
G1
G1 的 GC 流程:
- 初始标记(STW)
- 并发标记
- 最终标记(STW,此时会处理一些 SATB write barrier 记录的引用队列)
- 清理(SWT,G1 的清理阶段是 STW 的)
相关参数
| 参数 | 作用 | 默认值 |
|---|---|---|
| -XX:+UseG1GC | 使用G1收集器 | |
| -XX:G1HeapRegionSize | G1 中单个 Region 的大小 | |
| -XX:MaxGCPauseMillis | 期望的 G1 GC 停顿时间,GC 时会尽量靠近这个值 | 默认 200ms,过小会导致频繁 GC |
| -XX:InitiatingHeapOccupancyPercent | 设置触发标记周期的 Java 堆占用率阈值,在整堆占用超过该值开始进行并发标记 | 45% |
| -XX:ParallelGCThreads | 指定GC工作的线程数量 | |
| -XX:G1NewSizePercent | 新生代内存初始空间 | 整堆的5% |
| -XX:G1ReservePercent | 保留一部分空间,防止并发收集失败 | 10% |
CMS
CMS 是实际意义上第一个并行的垃圾收集器,垃圾收集线程和用户线程同时进行,JDK9 被标记弃用,JDK14 被删除。
CMS 的 GC 流程:
- 初始标记(SWT)
- 并发标记
- 最终标记(SWT,CMS 会扫描整个年轻代以及 GC ROOT,外带写屏障记录下来的引用 )
- 并发清理
CMS 将原先的 GC 划分阶段,只有在不得不 STW 的阶段才会进入 STW 的状态,从而减少整体的 STW 时间,提高应用整体的吞吐率。
CMS 的缺点
- 无法处理浮动垃圾 - (并发标记的过程中出现的垃圾
- 对 CPU 敏感,因为是和 Mutator 并行的,需要适当控制并发的 GC 线程数
- 严重的内存碎片,因为 CMS 是基于标记-清除算法
相关参数
| 参数 | 作用 | 默认值 |
|---|---|---|
| -XX: CMSInitiatingOccupancyFraction | 设置老年代 GC 的触发阈值,这里的阈值是指老年代对象占比。 | 92% |
| -XX:+UseCMSInitiatingOccupancyOnly | 仅遵循设置的触发阈值不会自动调整。 | 默认为空,不晋升。 |
| -XX: +CMSParallelRemarkEnabled | 在 CMS 开始前触发一次 YGC,以减少对年轻代的扫描。 | false |
| -XX: CMSFullGCsBeforeCompaction | 该参数表示经过几次 GC 之后进行整理。 | 默认为 0,表示每次都会进行整理 |
| -XX:UseCMSCompactAtFullCollection | 控制 Full GC的过程中是否进行空间的整理,配置之后每次 Full GC 都会进行一次空间整理(注意是Full GC,不是普通CMS GC) | 默认为 true |
参考
Parallel Scavenge
通过 -XX:+UseParallelGC 和 -XX:+UseParallelOldGC 两种开启该回收器。
前者配合 Serial Old 垃圾回收器,后者配合 Parallel Old 垃圾回收器。
该垃圾回收器默认启动了 AdaptiveSizePolicy,会根据 GC 的情况自动计算计算 Eden、From 和 To 区的大小。
可能会存在 From 和 To 被调整到只有不到 10M 的情况,此时如果遇到 YGC,很可能因为 Survivor 区溢出而导致存活对象全部晋升到老年代,如果配合的是 Serial 垃圾回收器,就会产生较大的延迟。
以通过如下控制该参数:
关闭:-XX:-UseAdaptiveSizePolicy
开启:-XX:+UseAdaptiveSizePolicy
参考
ParNew
相关参数
| 参数 | 作用 | 默认值 |
|---|---|---|
| -XX:ParallelGCThreads | 并发收集时候线程数 |
相关定义
什么是 Full GC ?
Full GC 是收集整个堆的 GC,主要是老年代和新生代。
在部分 GC 清理老年代的垃圾的时候,一般都会顺便触发一次 Young GC,也就组成了 Full GC。
例如,Parallel Scavenge(-XX:+UseParallelGC)框架下,默认是在要触发full GC前先执行一次young GC。
还有 CMS 在触发之后,最终标记之前可能会触发一次 YGC,尽量降低年轻代的内存占用。
什么是浮动垃圾?
浮动垃圾就是在 GC 线程并行收集其间出现的垃圾。
以三色标记法为例,在迭代期间,从黑色节点出发的引用被断掉,就会导致后续节点全部变为浮动垃圾(如果没有别的黑色节点引用的话),该被回收的垃圾对象被被标记为黑色。
相关算法
对象存活判断
GC 算法就是需要收集死亡的对象(不再使用的对象),因此事先就要该先判断对象是否存活。、
对象是否存活的判断依据就是是否有强引用指向它。
引用计数(Reference Counting)
任何添加对象引用的过程添加计数,删除引用的时候减少计数,算法的实现非常简单,但是需要进一步处理循环引用的问题,以及如果非 GC ROOT 的引用是否有效的问题。
可达性分析
可达性分析算法是从目前确认存活的对象(GC ROOT)出发,递归所有的引用的对象,标记所有存活的对象,剩下的就是死亡的对象。
Hotspot 中的 GC ROOT 包含如下部分:
- JVM 栈上的对象(方法中的临时变量)
- 常量池中的对象(常量)
- JNI 的引用对象
- Class 中的类变量
可达性算法的具体实现可以看三色标记法,三色标记法在 G1 上就有实现,并且 Go 的垃圾收集也实现了该方法。
基础的 GC 算法
复制算法
复制算法会将整个区域划分为两种区域(Eden 和 Survivor),对象的初始内存分配只在 Eden 区进行。
如果 Eden 区分配失败或者别的原因,触发了 GC,此时 GC 后剩余的对象会被复制到 Survivor 区域。
复制算法不会存在内存碎片,但是会造成空间的浪费,部分空间需要空为 Survivor 区域,并且还需要大量的内存复制。
标记 - 清除
标记 - 清除算法,就是标记所有存活对象,并清除所有的非存活对象的方式(或者反过来)。
标记 - 清除算法的缺点非常明显,会造成非常明显的内存碎片,会造成大对象的分配困难,但是因为只是清除,所以算法的速度非常可观。·
标记 - 整理
标记 - 整理是在标记 - 清除的基础上增加了整理的流程,整理的过程可以完全避免内存复制。
标记 - 整理的优点就是没有内存碎片,但是它的速度会明显的下降,因为有一个整理的过程。所以对一次 GC 后,大部分对象存活的时候,该算法会有很明显的延迟。
分代 GC 算法
分代 GC 只要是将整个需要进行回收的区划分为不同的 generational,划分的依据就是对象的声明周期。
常见的 generation 有以下三种:
- 年轻代 / 新生代
- 老年代
- 永久代
年轻代的对象往往朝生夕死,老年代具有相对较长的生命周期,而永久代就入其名一样基本上是永久存在的对象。
划分好不同的 generation 之后,就是根据不同的区域执行不同的 GC 算法
Card Table - 卡表
Remembered Set 是一种抽象概念,而 Card Table 可以是 Remembered Set 的一种实现方式。
简单上理解 Card Table 就是内存区域状态的集合,实现可以直接使用字节数组,每个字节表示堆中的某片区域的状态。
用卡表记录跨代的对象应用,在进行 GC 的时候可以减少对非收集区域的扫描。
比如在收集年轻代的时候,年轻代的 GC 非常频繁,如果每次收集年轻代都需要扫描老年代会大大降低 GC 效率。
此时就可以将老年代的内存空间划分为单个的 Card Table,标记所有持有年轻代引用的内存区域为 Dirty,那么只需要扫描那些 Dirty 的区域就好了。
另外卡表如果说有缺点,那就是它的维护成本了,一般来说卡表的状态都会通过写屏障来完成,所有的相关引用操作都增加一个 Card Table 的修改流程,怎么也会损失部分性能。
How_actually Card Table and writer barrier works?
三色标记法
三色标记法是将对象划分为三种类型(划分到三个集合)的 BFS 算法。

图片来源:JVM 三色标记 增量更新 原始快照
对象被分为 黑,灰,白 三种,含义如下:
- 黑 - 已经扫描的存活对象
- 灰 - 待扫描的存活对象
- 白 - 尚未扫描的未知对象
算法流程如下:
- 初始所有的对象都为白色
- 将所有的 GC ROOT 中的对象添加到灰色集合
- 遍历灰色集合,将对象的所有引用对象添加到灰色集合,当前对象添加到黑色对象
- 重复步骤 3,直到没有灰色对象
算法结束后,所有的黑色对象为存活对象,白色对象即为垃圾对象。
单纯的三色标记需要 STW,来保证各个对象之间的引用不会变化。
并发标记如何解决漏标问题
默认使用三色标记迭代法确定对象的可达性,并且标记的都是存活对象。
G1 和 CMS 都是并发的垃圾回收器,这里的并发是指用户线程(mutator)和 GC 线程(collector)同时运行,和用户线程同时进行就有可以出现对象之间引用关系的变化,也会因此出现一些错误的情况:
- 错标
错标就是指将原本是垃圾的对象,标记为存活,导致其在这一轮的 GC 中没有被清除。
很明显的,错标会导致出现浮动垃圾。
错标出现的情况很简单,在迭代的过程中从黑色节点出发的引用被断开了。
- 漏标
漏标是在 GC 过程中非常严重的错误,主要是存活的对象没有被标记,而导致存活对象被回收。
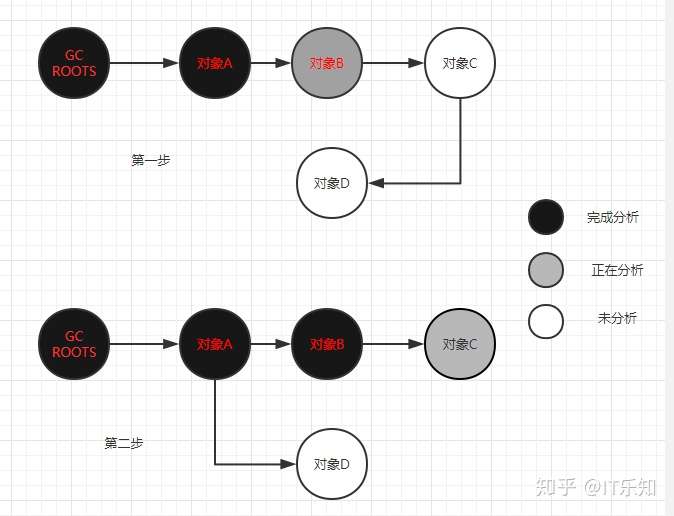
出现漏标问题需要满足以下两个条件:
- 收集期间删除了灰色到白色的引用(漏标的对象只能是白色的,灰色会被继续扫描,黑色已经标记存活
- 收集期间插入了一条从黑色节点出发的引用(黑色节点不会在扫描,如果引用从灰色节点出发会被继续扫描
首先明确,并发标记的时候新分配的对象都是存活对象,所以及时新增的对象肯定是存活的。
所以只有已经存在的对象之间的引用改变,会造成漏标。
所以只要破坏以上两者中的一个就可以解决漏标的问题,因此也就出现了两种解决方法:增量更新(Incremental Update)以及原始快照(SATB - Snapshot At The Beginning)。
增量更新破坏的是第一个条件,在新增一条引用的时候,将其记录保存。
原始快照破坏的是第二个条件,在灰色对象指向白色对象的引用被删除的时候也会被标记。
标记的特殊对象会在最终标记阶段被重新扫描。
对于 Hotspot 虚拟机来说,CMS 采用的是增量更新的方式(所以 CMS 会有一个重新标记的过程),而 G1 采用的是原始快照的方式。
参考
相关规则
Young GC 的触发条件
- Eden allocation failed (Eden 区分配失败 )
Full GC 的触发条件(非常重要)
- 老年代空间分配失败
- System.gc(),-XX:+DisableExplicitGC 为 false
- JMAP histo:live 等 JVM 内存查看命令
- 年轻代晋升担保失败
Survivor 溢出
在 Eden 回收之后存活的对象过多,无法放入 Survivor 区的时候,会直接晋升到老年代。
动态年龄计算
Hotspot 的实现中,除了满足 -XX:MaxTenuringThreshold 之外,还有一种动态的计算方式,简单来说,Survivor 区中相同年龄的对象占 Survivor 区一半的空间的时候,大于该年龄的对象会直接晋升到老年代
分配担保
需要确保老年代的剩余空间大于年轻代的存活对象,如果不满足先执行 Full GC。
相关参数
运行期相关
| 参数 | 作用 | 默认值 |
|---|---|---|
| -Xms | 堆的最小内存大小(使用中,应该尽量和 -Xmx 保持一致) | |
| -Xmx | 堆的最大内存大小 | |
| -XX:NewSize | 新生代的最小内存 | |
| -XX:MaxNewSize | 新生代的最大内存 | |
| -XX: Xss | 线程的堆栈大小 | 256k 合理 |
| -XX: SurvivorRatio | Eden 和 Survivor 比例控制 | 默认为8,比例为 8:1:1 |
| -XX: PreternureSizeThreshold | 直接晋升老年代的对象大小。 设置了这个参数后大于这个参数的对象直接在老年代进行分配。 |
默认为空,不晋升。 |
| -XX: MaxTenuringThreshold | 晋升老年代的对象年龄。 对象在每一次Minor GC后年龄增加一岁,超过这个值后进入到老年代。 |
默认值为15 |
| -XX: +DisableExplicitGC | 禁用显式 GC,开启该参数后 System.gc() 就不会触发一次 Full GC。 | true |
| -XX:+AlwaysPreTouch | -Xms 和 -Xmx 配置的堆大小只表示虚拟内存,并不会分配真实的物理内存,该参数会让 JVM 直接申请物理内存(填充0),但是应用的使用时间会拉长几个数量级 | |
| -XX:ConcGCThreads | 并行的线程数 | |
| -XX:ParallelGCThreads=n | 并发的线程数 |
调试相关
| 参数 | 作用 | 默认值 |
|---|---|---|
| -XX: +PrintFlagsInitial | 输出初始参数 | |
| -XX: +PrintFlagsFinal | 输出最终参数 | |
| -XX: +PrintTenuringDistribution | 该参数是个日志型参数,用于输出 Eden 区中对象年龄分布。 | false |
-XX: +PrintTenuringDistribution 的输出增加
Desired survivor size 107347968 bytes, new threshold 16 (max 30)
- age 1: 4345400 bytes, 4345400 total
- age 2: 2436856 bytes, 6782256 total
- age 3: 676112 bytes, 7458368 total
- age 4: 2323952 bytes, 9782320 total
- age 5: 599616 bytes, 10381936 total
- age 6: 563656 bytes, 10945592 total
- age 7: 567656 bytes, 11513248 total
- age 8: 815480 bytes, 12328728 total
- age 9: 527672 bytes, 12856400 total
- age 10: 3956032 bytes, 16812432 total
- age 11: 16575184 bytes, 33387616 total
: 1716581K->49462K(1887488K), 0.0345690 secs] 1739786K->72667K(3984640K), 0.0349280 secs] [Times: user=0.12 sys=0.00, real=0.04 secs]
-XX:+DisableExplicitGC 的副作用
Netty 中对直接内存的清理,是基于对 DirectByteBuffer 对象的显式回收,所以如果关闭该参数可能会在使用 Netty 等框架的时候出现堆外内存溢出。
CMS 和 G1 的比较
- G1 属于复制算法,而 CMS 是标记清除
- G1 是全代的垃圾收集器,会将堆分为 region,而 CMS 只负责老年代(需要和其他年轻代垃圾收集( ParNew 或者 Serial )配合。
- G1 使用原始快照保证并发标记的正确性,而 CMS 用的是增量更新
- CMS 会随着堆大小的变化而变化,老年代越大收集越慢,而 G1 不会(因为使用的 Region,会使用 RSet 选择效益比较高的区域收集,8~16g以下的内存 CMS 性能会更加优秀
- G1 分为 Young 和 Mixed GC,而 CMS 只有 Full GC(CMS 可以选择 GC 前先收集年轻代
- G1 使用全堆占用率作为触发阈值,而 CMS 使用老年代占用率作为触发阈值
- CMS 的收集过程是连续的,而 G1 会随时进行标记,结果保存到 RSet,最后触发收集
相关资料
GC参数解析 UseSerialGC、UseParNewGC、UseParallelGC、UseConcMarkSweepGC